
The 1st of July was the day that the OPIGlets went kayaking!
Brennan very kindly offered to guide a kayaking session from the Oxford University Canoeing and Kayaking Club (OUCKC). There was great uptake from the group, with 10 members joining for a paddle.
The first task was to find a kayak long enough for Jack’s legs. Once he managed to wedge himself in to the largest kayak available, we moved onto being pushed down the ramp one by one, hoping that this would not lead to an immediate capsize.
Continue reading

 into two sets – a training set
into two sets – a training set 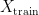 and a test set
and a test set 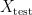 . The model is then subsequently trained on the examples in the training set
. The model is then subsequently trained on the examples in the training set 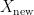 which it will encounter in the future. Right?
which it will encounter in the future. Right?