
Last week I discussed the recent paper by Lhota et al. proposing a network-based similarity search method, applied to the problem of protein fold prediction. Similarity search is the foundation of bioinformatics. It plays a key role in establishing structural, functional and evolutionary relationships between biological sequences. Although the power of the similarity search has increased steadily in recent years, a high percentage of sequences remain uncharacterized in the protein universe. Cumulative evidence suggests that the protein universe is continuous. As a result, conventional sequence homology search methods may be not able to detect novel structural, functional and evolutionary relationships between proteins from weak and noisy sequence signals. To overcome the limitations in existing similarity search methods, the authors propose a new algorithmic framework, Enrichment of Network Topological Similarity (ENTS). While the method is general in scope, in the paper, authors focus exclusively on the protein fold recognition problem.

Fig 1: ENTS pipeline for protein fold prediction.
To initialize ENTS for structure prediction, ENTS builds a structural similarity graph of protein domains (Fig 1). The structural similarity graph is a weighted graph with one node for each structural domain and an edge between two nodes only if their pairwise similarity exceeds a certain threshold. In this article, the structural similarity score is determined by TM align with a threshold of 0.4. Next, some or all the structural domains in the database are labeled with SCOP. Given a query domain sequence and the goal to predict its structure, ENTS first links the query to all nodes in the structural similarity graph. The weights of these new edges are based only on the sequence profile-profile similarity derived from HHSearch. Then random walk with restart (RWR) is applied to perform a probabilistic traversal of the instance graph across all paths leading away from the query, where the probability of choosing an edge will be proportional to its weight. The algorithm will output a ranked list of probabilities of reaching each node in the structural graph from the query, thus potentially uncovering relationships missed by pair-wise comparison methods. ENTS also uses an enrichment analysis step to assess the reliability of the detected relationships, by comparing the mean relationship strength of a SCOP cluster in the structural graph and the query, to that of random clusters.
For testing the method, the authors first constructed a structural graph using 36,003 non-redundant protein domains from the PDB. The query benchmark set consisted of 885 SCOP domains, constructed by randomly selecting each domain from folds spanning at least two super-families. An additional step before prediction on the query set was to remove all domains from the structral graph which were in the same super-family as the query. The method was compared to existing methods such as CNFPred and HHSearch and it’s network approach and enrichment analysis step were found to contribute significantly to the accuracy of fold prediction. While the method seems to be an improvement on existing methods and is a novel use of network-based approaches to fold prediction, the false positive rate is still very high. One way of overcoming this, suggested by the authos is the use of energy-based scoring functions to further prune the list of potential hits returned by the method.



 communities and that each node
communities and that each node  is associated with a vector of community memberships
is associated with a vector of community memberships 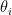 . To generate a network, the model considers each pair of nodes. For each pair
. To generate a network, the model considers each pair of nodes. For each pair 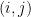 , it chooses a community indicator
, it chooses a community indicator 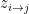 from the
from the 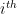 node’s community memberships
node’s community memberships 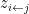 from
from  . A connection is then drawn between the nodes with probability
. A connection is then drawn between the nodes with probability  if the indicators point to the same community or with a smaller probability
if the indicators point to the same community or with a smaller probability  if they do not.
if they do not.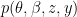 where
where  is the observed data. To estimate the posterior
is the observed data. To estimate the posterior 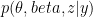 , the method uses a stochastic variational inference algorithm. This enables posterior estimation using only a sample of all-possible node pairs at each step of the variational inference, making the method applicable to very large graphs (e.g analyzing a large citation network of physics papers shown in the figure below identifies important papers impacting several sub-disciplines).
, the method uses a stochastic variational inference algorithm. This enables posterior estimation using only a sample of all-possible node pairs at each step of the variational inference, making the method applicable to very large graphs (e.g analyzing a large citation network of physics papers shown in the figure below identifies important papers impacting several sub-disciplines).