
Detecting overlapping communities is essential to analyzing and exploring natural networks such as social networks, biological networks, and citation networks. However, most existing approaches do not scale to the size of networks that we regularly observe in the real world. In the paper by Gopalan et al. discussed in this week’s group meeting, a scalable approach to community detection is developed that discovers overlapping communities in massive real-world networks. The approach is based on a Bayesian model of networks that allows nodes to participate in multiple communities, and a corresponding algorithm that naturally interleaves subsampling from the network and updating an estimate of its communities.
The model assumes there are 

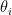
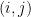
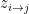
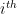
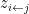



This model defines a joint probability 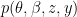

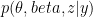

Community detection in a physics citation network.
One limitation of the method is that it does not incorporate automatic estimation of the number of communities, which is a general problem with clustering algorithms. Still, enabling sophisticated probabilistic analysis of structure in massive graphs is a significant step forward.