Before I start with my musings about my work and the topic of my D. Phil thesis, I would like to direct you to a couple of previous entries here on BLOPIG. If you are completely new to the field of protein structure prediction or if you just need to refresh your brain a bit, here are two interesting pieces that may give you a bit of context:
A very long introductory post about protein structure prediction
and
de novo Protein Structure Prediction software: an elegant “monkey with a typewriter”
Brilliant! Now, we are ready to start.
In this OPIG group meeting, I presented some results that were obtained during my long quest to predict protein structures.
Of course, no good science can happen without the postulation of question-driving hypotheses. This is where I will start my scientific rant: the underlying hypotheses that inspired me to inquire, investigate, explore, analyse, and repeat. A process all so familiar to many.
As previously discussed (you did read the previous posts as suggested, didn’t you?), de novo protein structure prediction is a very hard problem. Computational approaches often struggle to search the humongous conformational space efficiently. Who can blame them? The number of possible protein conformations is so astronomically large that it would take MUCH longer than the age of the universe to look at every single possible protein conformation.
If we go back to biology, protein molecules are constantly undergoing folding. More so, they manage to do so efficiently and accurately. How is that possible? And can we use that information to improve our computational methods?
The initial hypothesis we formulated in the course of my degree was the following:
“We [the scientific community] can benefit from better understanding the context under which protein molecules are folding in vivo. We can use biology as a source of inspiration to improve existing methods that perform structure prediction.”
Hence came the idea to look at biology and search for inspiration. [Side note: It is my personal belief that there should be a back and forth process, a communication, between computational methods and biology. Biology can inspire computational methods, which in turn can shed light on biological hypotheses that are hard to validate experimentally]
To direct the search for biological inspiration, it was paramount to understand the limitations of current prediction methods. I have narrowed down the limitations of de novo protein structure prediction approaches to three major issues:
1- The heuristics that rely on sampling the conformational space using fragments extracted from know structures will fail when those fragments do not encompass or correctly describe the right answer.
2- Even when the conformational space is reduced, say, to fragment space, the combinatorial problem persists. The energy landscape is rugged and unrepresentative of the actual in vivo landscape. Heuristics are not sampling the conformational space efficiently.
3- Following from the previous point, the reason why the energy landscape is unrepresentative of the in vivo landscape is due to the inaccuracy of the knowledge-based potentials used in de novo structure prediction.
Obviously, there are other relevant issues with de novo structure prediction. Nonetheless, I only have a limited amount of time for my D.Phil and those are the limitations I decided to focus on.
To counter each of these offsets, we have looked for inspiration in biology.
Our understanding from looking at different protein structures is that several conformational constraints are imposed by alpha-helices and beta-strands. That is a consequence of hydrogen bond formation within secondary structure elements. Unsurprisingly, when looking for fragments that represent the correct structure of a protein, it is much easier to identify good fragments for alpha-helical or beta-strand regions. Loop regions, on the other hand, are much harder to be described correctly by fragments extracted from known structures. We have incorporated this important information into a fragment library generation software in an attempt to address limitation number 1.
We have investigated the applicability of a biological hypothesis, cotranslational protein folding, into a structure prediction context. Cotranslational protein folding is the notion that some proteins begin their folding process as they are being synthesised. We further hypothesise that cotranslational protein folding restricts the conformational space, promoting the formation of energetically-favourable intermediates, thus steering the folding path towards the right conformation. This hypothesis has been tested in order to improve the efficiency of the heuristics used to search the conformational space.
Finally, following the current trend in protein structure prediction, we used evolutionary information to improve our knowledge-based potentials. Many methods now consider correlated mutations to improve their predictions, namely the idea that residues that mutate in a correlated fashion present spatial proximity in a protein structure. Multiple sequence alignments and elegant statistical techniques can be used to identify these correlated mutations. There is a substantial amount of evidence that this correlated evolution can significantly improve the output of structure prediction, leading us one step closer to solving the protein structure prediction problem. Incorporating this evolution-based information into our routine assisted us in addressing the lack of precision of existing energy potentials.
Well, does it work? Surprisingly or not, in some cases it does! We have participated in a blind competition: the Critical Assessment for protein Structure Prediction (CASP). This event is rather unique and it brings together the whole structure prediction community. It also enables the community to gauge at how good we are at predicting protein structures. Working with completely blind predictions, we were able to produce one correct answer, which is a good thing (I guess).
All of this comes together nicely in our biologically inspired pipeline to predict protein structures. I like to think of our computational pipeline as a microscope. We can use it to prod and look at biology. We can tinker with hypotheses, implement potentials and test them, see what is useful for us and what isn’t. It may not be exactly what get the papers published, but the investigative character of our structure prediction pipeline is definitely the favourite aspect of my work. It is the aspect that makes me feel like a scientist.
Protein Structure Prediction, my own metaphorical microscope…






 of being present).
of being present).
 . The probability of obtaining an edge between nodes i and j is given by
. The probability of obtaining an edge between nodes i and j is given by 

![[0,1]^d](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5Ed&bg=ffffff&fg=000&s=0&c=20201002) . Now, given a radius or threshold distance (r), edges are drawn among nodes
. Now, given a radius or threshold distance (r), edges are drawn among nodes 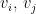
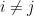 if
if  .
.











