
5 Thoughts For… Comparing Crystallographic Datasets
Most of the work I do involves comparing diffraction datasets from protein crystals. We often have two or more different crystals of the same crystal system, and want to spot differences between them. The crystals are nearly isomorphous, so that the structure of the protein (and crystal) is almost identical between the two datasets. However, it’s not just a case of overlaying the electron density maps, subtracting them and looking at the difference. Nor do we necessarily want to calculate Fo-Fo maps, where we calculate the difference by directly subtracting the diffraction data before calculating maps. By the nature of the crystallographic experiment, no two crystals are the same, and two (nearly identical) crystals can lead to two quite different datasets.
So, here’s a list of things I keep in mind when comparing crystallographic datasets…
Control the Resolution Limits
1) Ensure that the resolution limits in the datasets are the same, both at the high AND the low resolution limits.
The High resolution limit. The best known, and (usually) the most important statistic of a dataset. This is a measure of the amount of information that’s been collected about the dataset. Higher resolution data gives more detail for the electron density. Therefore, if you compare a 3A map to a 1A map, you’re comparing fundamentally different objects, and the differences between them will be predominantly from the different amount of information in each dataset. It’s then very difficult to ascertain what’s interesting, and what is an artefact of this difference. As a first step, truncate all datasets at the resolution you wish to compare them at.
The Low Resolution Limit. At the other end of the dataset, there can be differences in the low resolution data collected. Low resolution reflections correspond to much larger-scale features in the electron density. Therefore, it’s just as important to have the same low-resolution limit for both datasets, otherwise you get large “waves” of electron density (low-frequency fourier terms) in one dataset that are not present in the other. Because low-resolution terms are much stronger than high resolution reflections, these features stand out very strongly, and can also obscure “real” differences between the datasets you’re trying to compare. Truncate all datasets at the same low resolution limit as well.
Consider the Unit Cell
2) Even if the resolution limits are the same, the number of reflections in maps can be different.
The Unit Cell size and shape. Even if the crystals you’re using are the same crystal form, no two crystals are the same. The unit cell (the building block of the crystal) can be slightly different sizes and shapes between crystals, varying in size by a few percent. This can occur by a variety of reasons, from the unpredictable process of cooling the crystal to cryogenic temperatures to entirely stochastic differences from the process of crystallisation. Since the “resolution” of reflections depends on the size of the unit cell, two reflections with the same miller index can have different “resolutions” when it comes to selecting reflections for map calculation. Therefore, if you’re calculating maps from nearly-isomorphous but non-identical crystals, consider calculating maps based on an high and a low miller index cutoff, rather than a resolution cutoff. This ensures the same amount of information in each map (number of free parameters).
Watch for Missing Reflections
3) Remove any missing reflections from both datasets.
Reflections can be missing from datasets for a number of reasons, such as falling into gaps/dead pixels on the detector. However, this isn’t going to happen systematically with all crystals, as different crystals will be mounted in different orientations. When a reflection is missed in one dataset, it’s best to remove it from the dataset you’re comparing it to as well. This can have an important effect when the completeness of low- or high-resolution shells is low, whatever the reason.
Not All Crystal Errors are Created Equal…
4) Different Crystals have different measurement errors.
Observation uncertainties of reflections will vary from crystal to crystal. This may be due to a poor-quality crystal, or a crystal that has suffered from more radiation damage than another. These errors lead to uncertainty and error in the electron density maps. Therefore, if you’re looking for a reference crystal, you probably want to choose one with as small uncertainties, σ(F), in the reflections as possible.
Proteins are Flexible
5) Even though the crystals are similar, the protein may adopt slightly difference conformations.
In real-space, the protein structure varies from crystal to crystal. For the same crystal form, there will be the same number of protein copies in the unit cell, and they will be largely in the same conformation. However, the structures are not identical, and the inherent flexibility of the protein can mean that the conformation seen in the crystal can change slightly from crystal to crystal. This effect is largest in the most flexible regions of the protein, such as unconstrained C- and N- termini, as well as flexible loops and crystal contacts.







 of being present).
of being present).
 . The probability of obtaining an edge between nodes i and j is given by
. The probability of obtaining an edge between nodes i and j is given by 

![[0,1]^d](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5Ed&bg=ffffff&fg=000&s=0&c=20201002) . Now, given a radius or threshold distance (r), edges are drawn among nodes
. Now, given a radius or threshold distance (r), edges are drawn among nodes 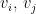
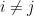 if
if  .
.


