
When you wrangle data for a living, you start to wonder why everything takes so darn long. Through five years of introspection, I have come to conclude that two simple factors limit every computational project. One is, of course, your personal productivity. Your time of focused work, minus distractions (and yes, meetings figure here), times your energy and mental acuity. All those things you have little control over, unfortunately. But the second is the productivity of your code and tools. And this, in principle, is a variable that you have full control over.

This is a post about how to increase your productivity, by helping you navigate all those instances when the progress bar does not seem to go fast enough. I want to discuss actionable tools to make your code run faster, and generate more results, with less effort, in less time. Instructions to tinker less and think more, so you can do the science that you truly want to be doing. And, above all, I want to give out advice that is so counter-intuitive that you should absolutely consider following it.
Continue reading
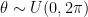 . Extending this idea to 3D rotations, we could sample each of the three Euler angles from the same uniform distribution
. Extending this idea to 3D rotations, we could sample each of the three Euler angles from the same uniform distribution 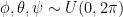 . This, however, gives more probability density to transformations which are clustered towards the poles:
. This, however, gives more probability density to transformations which are clustered towards the poles:
 into two sets – a training set
into two sets – a training set 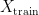 and a test set
and a test set 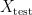 . The model is then subsequently trained on the examples in the training set
. The model is then subsequently trained on the examples in the training set 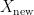 which it will encounter in the future. Right?
which it will encounter in the future. Right?