
Hi everyone,
My blogpost this time around is a list of conferences popular with OPIGlets. You are highly likely to see at least one of us attending or presenting at these meetings! I’ve tried to make it as exhaustive as possible (with thanks to Fergus Imrie!), listing conferences in upcoming chronological order.
(Most descriptions are slightly modified snippets taken from the official websites.)
Category Archives: Networks
Just Call Me EEGor
Recently, I was lucky enough to assist in (who am I kidding…obstruct) a sleep and anaesthesia study aimed at monitoring participants by Electroencephalogram (EEG) in various states of consciousness. The study, run by Dr Katie Warnaby of The Anaesthesia Neuroimaging Research Group at The Nuffield Department of Clinical Neuroscience, makes use of both EEG and functional Magnetic Resonance Imaging (fMRI). The research aim is to learn about the effects anaesthesia has on the brain and and in so doing help us both understand ourselves and understand how to most effectively monitor patients undergoing surgery.
Continue readingKernel Methods are a Hot Topic in Network Feature Analysis
The kernel trick is a well known method in machine learning for producing a real-valued measure of similarity between data points in any number of settings. Kernel methods for network analysis provide a way of assigning real values to vertices of the graph. These values may correspond to similarity across any number of graphical properties such as the neighbours they share, or more dynamic context, the influence that change in the state of one vertex might have on another.
By using the kernel trick it is possible to approximate the distribution of features on the vertices of a graph in a way that respects the graphical relationships between vertices. Kernel based methods have long been used, for instance in inferring protein function from other proteins within Protein Interaction Networks (PINs).
Continue ReadingGraph-based Methods for Cheminformatics
In cheminformatics, there are many possible ways to encode chemical data represented by small molecules and proteins, such as SMILES, fingerprints, chemical descriptors etc. Recently, utilising graph-based methods for machine learning have become more prominent. In this post, we will explore why representing molecules as graphs is a natural and suitable encoding. Continue reading
Neuronal Complexity: A Little Goes a Long Way…To Clean My Apartment
The classical model of signal integration in both biological and Artificial Neural Networks looks something like this,
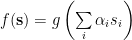
where 
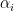
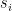

See more at Khan Academy
Models of learning and memory have relied heavily on modifications to the PSD to explain modifications in behaviour. Physically these changes result from alterations in the concentration and density of the neurotransmitter receptors and ion channels that occur in abundance at the PSD, but, in actuality these channels occur all along the cell wall of the dendrite on which the PSD is located. Dendrites are something like a multi-branched mass of input connections belonging to each neuron. This begs the question as to whether learning might in fact occur all along the length of each densely branched dendritic tree.
Protein Interaction Networks
Proteins don’t just work in isolation, they form complex cliques and partnerships while some particularly gregarious proteins take multiple partners. It’s becoming increasingly apparent that in order to better understand a system, it’s insufficient to understand its component parts in isolation, especially if the simplest cog in the works end up being part of system like this.
On a macroscopic scale, a cell doesn’t care if the glucose it needs comes from lactose, converted by lactase into galactose and glucose, or from starch converted by amalase, or from glycogen, or from amino acids converted by gluconeogenesis. All it cares about is the glucose. If one of these multiple pathways should become unavailable, as long as the output is the same (glucose) the cell can continue to function. At a lower level, by forming networks of cooperating proteins, these increase a system’s robustness to change. The internal workings may be rewired, but many systems don’t care where their raw materials come from, just so long as they get them.
Whilst sequence similarity and homology modelling can explain the structure and function of an individual protein, its role in the greater scheme of things may still be in question. By modelling interaction networks, higher level questions can be asked such as: ‘What does this newly discovered complex do’? – ‘I don’t know, but yeast’s got something that looks quite like it.’ Homology modelling therefore isn’t just for single proteins.
Scoring the similarity of proteins in two species can be done using many non-exclusive metrics including:
Subsequently clustering these proteins based on their interaction partners, highlights the groups of proteins which form functional units. These are highly connected internally whilst having few edges to adjacent clusters. This can provide insight into previously un-investigated proteins which by virtue of being in a cluster of known purpose, their function can be inferred.