If you want to skip the small talk, the code is at the bottom. Sampling 2D rotations uniformly is simple: rotate by an angle from the uniform distribution . Extending this idea to 3D rotations, we could sample each of the three Euler angles from the same uniform distribution . This, however, gives more probability density to transformations which are clustered towards the poles:
Sampling Euler angles uniformly does not give an even distribution across the sphere.
Have you ever tried to use someone else’s code and spent a whole day trying to install it? Have you ever decided not to use a tool because installing it was a massive pain? Both of those have happened to me and, to be honest, it is a massive shame. The authors may spend large amounts of time developing these tools and in the end, no one uses them because they can’t get them to work. So I have decided to try and make all code I develop as easy and painless as possible to install and use.
Don’t get me wrong. I love Linux. After many years of using it, I ended up appreciating how flexible, potent, and even beautiful it is. However, using Linux has never been a bed of roses and every single Linux user that I know has had to deal with many problems since the very beginning. Indeed, I still remember how frustrating installing my first Linux machine was, especially after realizing that my network card was not working. Had I given up, I would never have written this post.
Although many of the problems that I faced while using Linux are related to updates and drivers (how painful NVidia drivers updates can be, I will write another post about that in the future), I must recognize that on many other occasions I was the only one responsible for such problems. Consequently, I want to warn the reader against a couple of those mistakes I made in the past and provide some tips about how to deal with them.
Detecting intermolecular interactions is often one of the first steps when assessing the binding mode of a ligand. This usually involves the human researcher opening up a molecular viewer and checking the orientations of the ligand and protein functional groups, sometimes aided by the viewer’s own interaction detecting functionality. For looking at single digit numbers of structures, this approach works fairly well, especially as more experienced researchers can spot cases where the automated interaction detection has failed. When analysing tens or hundreds of binding sites, however, an automated way of detecting and recording interaction information for downstream processing is needed. When I had to do this recently, I used an open-source Python module called ODDT (Open Drug Discovery Toolkit, its full documentation can be found here).
My use case was fairly standard: starting with a list of holo protein structures as pdb files and their corresponding ligands in .sdf format, I wanted to detect any hydrogen bonds between a ligand and its native protein crystal structure. Specifically, I needed the number and name of the the interacting residue, its chain ID, and the name of the protein atom involved in the interaction. A general example on how to do this can be found in the ODDT documentation. Below, I show how I have used the code on PDB structure 1a9u.
A common way of deploying a Flask web application in a production environment is to use an Apache server with the mod_wsgi module, which allows Apache to host any application that supports Python’s Web Server Gateway Interface (WSGI), making it quick and easy to get an application up and running. In this post, we’ll go through configuring your Apache server to host multiple Python apps in a stable manner, including how to run apps in daemon mode and avoiding hanging processes due to Python C extensions not working well with Python sub-interpreters (I’m looking at you, numpy).
A week ago I participated in Copenhagen Bioinformatics Hackathon 2021, a hackathon focusing on machine learning and proteins, as a mentor for a challenge proposed by our group. The whole experience was fun, but I am also sitting here contemplating over a lot of things I wish I had done differently. For this blog text, I therefore want to highlight two changes which I believe would have greatly improved my challenge and which can hopefully also work as an inspiration for others presenting a hackathon challenge.
Going into this event I had some experience from a few hackathons I had previously attended. Based on this, I wanted to create a challenge containing two parts. First, a simple task which everyone would be able to create a solution for, and second, a more challenging addition to the first task for more experienced participants. I decided to go with the challenge of predicting which heavy and light chains can form a pair, where the additional challenge was to try to visualize which residues were relevant for this interaction. Together with OAS containing a really nice positive dataset of paired chains, I thought this was going to be an amazing challenge, but as soon as the event began I started seeing the flaws of the challenge.
Have you ever worked with a piece of software that is awfully difficult to set up? That legacy code written on FORTRAN 77, that other one that requires significant modifications to compile, or any of those that require a long-winded bash script with a thousand dependencies (which you also have to install!). Would it not be helpful if, when that red-eyed PhD student, that one that just spent three months writing up their thesis, says that they absolutely must use that server where you have installed all your stuff, you could just relocate to another one without trouble? Well, you may be able to do that now. You just need to use containerization.
The idea behind containerization is rather simple. The best way to ensure anyone can reproduce your work is to, well, ship your entire system to whomever needs to use it. You could, for example, pack up your desktop in a box, and ship it to your collaborators anywhere in the world. Unfortunately, this idea is quite unpractical, not only because of tedious logistics (ever had to deal with customs?), but also because suddenly you won’t be able to run your own pipeline. However, it is a good enough thought that at some point made a clever engineer wonder whether there was a way to ship an entire system without physically delivering the computer. And that’s exactly what they designed.
Best way to make sure your collaborators on the other side of the world can run your pipeline — just pack your desktop in one of these, and ship it away!Continue reading →
Although correlation is often used as the linear relationship between two sets of points, I will in the following text use it more broadly to mean any relationship between two sets of points.
You have tasked yourself with finding the correlation between the different features in your dataset. Your purpose could be to remove highly correlated features or just improve your understanding of your data. Nonetheless, calculating and using the Pearson Correlation Coefficient (PCC) or the Spearman’s rank Correlation Coefficient (SCC) to get an overview of the correlations might be the first thing that comes to your mind.
Unfortunately, both of these are limited to linear (PCC) or monotonic (SCC) relationships. In datasets with many and complex features, many of them will be highly correlated, just not linearly (or monotonic). Instead these correlations can be non-linear which, as seen in the third row in the below figure, does not get detected with PCC.
Peer review is an important component of academic research and publishing, but it can feel like an opaque process, especially for those not directly involved. I am very fortunate to have been able to participate in the peer review of multiple papers, despite being very early in my career, through support from my supervisors and a mentoring program run by Sense about Science with Nature Communications. Here are some of the things I have learned.
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.

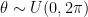




{kind=link}