
As a reasonably new RDKit user, I was relieved to find that using its built-in functionality for generating basic images from molecules is quite easy to use. However, over time I have picked up some additional tricks to make the images generated slightly more pleasing on the eye!
The first of these (which I definitely stole from another blog post at some point…) is to ask it to produce SVG images rather than png:
#ensure the molecule visualisation uses svg rather than png format IPythonConsole.ipython_useSVG=True
Now for something slightly more interesting: as a fragment elaborator, I often need to look at a long list of elaborations that have been made to a starting fragment. As these have usually been docked, these don’t look particularly nice when loaded straight into RDKit and drawn:
#load several mols from a single sdf file using SDMolSupplier
#add these to a list
elabs = [mol for mol in Chem.SDMolSupplier('frag2/elabsTestNoRefine_Docked_0.sdf')]
#get list of ligand efficiencies so these can be displayed alongside the molecules
LEs = [(float(mol.GetProp('Gold.PLP.Fitness'))/mol.GetNumHeavyAtoms()) for mol in elabs]
Draw.MolsToGridImage(elabs, legends = [str(LE) for LE in LEs])

Two quick changes that will immediately make this image more useful are aligning the elaborations by a supplied substructure (here I supplied the original fragment so that it’s always in the same place) and calculating the 2D coordinates of the molecules so we don’t see the twisty business happening in the bottom right of Fig. 1:
Continue reading into two sets – a training set
into two sets – a training set 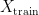 and a test set
and a test set 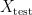 . The model is then subsequently trained on the examples in the training set
. The model is then subsequently trained on the examples in the training set 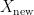 which it will encounter in the future. Right?
which it will encounter in the future. Right?