Recently I was dealing with a set of compounds with known target activities from the ChEMBL database, and I wanted to find out which of them also had PDB crystal structures in complex with that target.
Referencing this manually is very easy for cases where we are interested in 2-3 compounds, but for any larger number, using the ChEMBL and PDB web services greatly reduces the number of clicks.
There are more python libraries than you can shake a stick at, but here are a handful that don’t get much love and may save you some brain power, compute time or both.
Fire is a library which turns your normal python functions into command-line utilities without requiring more than a couple of additional lines of copy-and-paste code. Being able to immediately access your functions from the command line is amazingly helpful when you’re making quick and dirty utilities and saves needing to reach for the nuclear approach of using getopt.
If you want to skip the small talk, the code is at the bottom. Sampling 2D rotations uniformly is simple: rotate by an angle from the uniform distribution . Extending this idea to 3D rotations, we could sample each of the three Euler angles from the same uniform distribution . This, however, gives more probability density to transformations which are clustered towards the poles:
Sampling Euler angles uniformly does not give an even distribution across the sphere.
Nature has now released that AlphaFold 2 paper, after eight long months of waiting. The main text reports more or less what we have known for nearly a year, with some added tidbits, although it is accompanied by a painstaking description of the architecture in the supplementary information. Perhaps more importantly, the authors have released the entirety of the code, including all details to run the pipeline, on Github. And there is no small print this time: you can run inference on any protein (I’ve checked!).
Have you not heard the news? Let me refresh your memory. In November 2020, a team of AI scientists from Google DeepMind indisputably won the 14th Critical Assessment of Structural Prediction competition, a biennial blind test where computational biologists try to predict the structure of several proteins whose structure has been determined experimentally but not publicly released. Their results were so astounding, and the problem so central to biology, that it took the entire world by surprise and left an entire discipline, computational biology, wondering what had just happened.
The ability to successfully apply previously acquired knowledge to novel and unfamiliar situations is one of the main hallmarks of successful learning and general intelligence. This capability to effectively generalise is amongst the most desirable properties a prediction model (or a mind, for that matter) can have.
In supervised machine learning, the standard way to evaluate the generalisation power of a prediction model for a given task is to randomly split the whole available data set into two sets – a training set and a test set . The model is then subsequently trained on the examples in the training set and afterwards its prediction abilities are measured on the untouched examples in the test set via a suitable performance metric.
Since in this scenario the model has never seen any of the examples in during training, its performance on must be indicative of its performance on novel data which it will encounter in the future. Right?
Have you ever worked with a piece of software that is awfully difficult to set up? That legacy code written on FORTRAN 77, that other one that requires significant modifications to compile, or any of those that require a long-winded bash script with a thousand dependencies (which you also have to install!). Would it not be helpful if, when that red-eyed PhD student, that one that just spent three months writing up their thesis, says that they absolutely must use that server where you have installed all your stuff, you could just relocate to another one without trouble? Well, you may be able to do that now. You just need to use containerization.
The idea behind containerization is rather simple. The best way to ensure anyone can reproduce your work is to, well, ship your entire system to whomever needs to use it. You could, for example, pack up your desktop in a box, and ship it to your collaborators anywhere in the world. Unfortunately, this idea is quite unpractical, not only because of tedious logistics (ever had to deal with customs?), but also because suddenly you won’t be able to run your own pipeline. However, it is a good enough thought that at some point made a clever engineer wonder whether there was a way to ship an entire system without physically delivering the computer. And that’s exactly what they designed.
Best way to make sure your collaborators on the other side of the world can run your pipeline — just pack your desktop in one of these, and ship it away!Continue reading →
In preparation for remote teaching this year, I’ve spent the last few weeks converting the Doctoral Training Centre’s ‘Introduction to Computer Programming’ course into a series of Jupyter notebooks so that the course can be run entirely using Google Colaboratory.
Both the beauty and the downfall of learning-based methods is that the data used for training will largely determine the quality of any model or system.
While there have been numerous algorithmic advances in recent years, the most successful applications of machine learning have been in areas where either (i) you can generate your own data in a fully understood environment (e.g. AlphaGo/AlphaZero), or (ii) data is so abundant that you’re essentially training on “everything” (e.g. GPT2/3, CNNs trained on ImageNet).
This covers only a narrow range of applications, with most data not falling into one of these two categories. Unfortunately, when this is true (and even sometimes when you are in one of those rare cases) your data is almost certainly biased – you just may or may not know it.
Scientific code is never fast enough. We need the results of that simulation before that pressing deadline, or that meeting with our advisor. Computational resources are scarce, and competition for a spot in the computing nodes (cough, cough) can be tiresome. We need to squeeze every ounce of performance. And we need to do it with as little effort as possible.
Docker is an excellent containerisation system ideally suited to production servers. It allows you to do one small thing but do it well. For example, breaking a large blog up into individually maintained containers for a web-server, a database and (say) a wordpress instance. However due to inherent security woes, Docker doesn’t play nicely with multi-tenanted machines, the kind which are the bread and butter for researchers and HPC users. That’s where Singularity steps in.

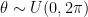 . Extending this idea to 3D rotations, we could sample each of the three Euler angles from the same uniform distribution
. Extending this idea to 3D rotations, we could sample each of the three Euler angles from the same uniform distribution 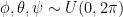 . This, however, gives more probability density to transformations which are clustered towards the poles:
. This, however, gives more probability density to transformations which are clustered towards the poles:

 into two sets – a training set
into two sets – a training set 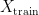 and a test set
and a test set 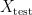 . The model is then subsequently trained on the examples in the training set
. The model is then subsequently trained on the examples in the training set 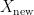 which it will encounter in the future. Right?
which it will encounter in the future. Right?